※ 실제 테이블 구조가 아닌 이해를 돕기 위해 간단하게 재구성 한 구조 입니다.
이해를 돕기 위해 변경 전 테이블 구조를 먼저 보여주고 고도화 요구사항을 설명하고 변경한 테이블 구조에 대해서 설명합니다.
index, 데이터 양을 중점으로 생각해서 테이블을 설계하였습니다.
마지막에는 index에 대해서 정리한 내용을 설명합니다.
변경 전 테이블 구조 흐름
1. 고객 정보를 등록
2. 메신저를 보낸다
-> 소통 내용 태이블에 INSERT
-> 소통 ID를 고객별 마지막 소통 ID 컬럼에 UPDATE
3. 고객별 대화 내용 조회
(쉽게 말해서 카카오톡에서 대화 목록을 보여준다고 생각하면 된다. 대화 목록에는 마지막으로 연락한 메세지 내용이 보인다.)
-> 소통 내용에 많은 데이터가 쌓이기 때문에 LATEST_COMMUNICATION 을 이용해서 빠르게 조회할 수 있도록 하였다. 만약 LATEST_COMMUNICATION이 없다면 날짜 OR ID를 이용해 GROUP BY MAX()를 해야 한다. 매우 느려질 수 있다.
4. 대화 내용 조회
-> CUSTOMER_ID로 소통 내용 테이블에서 조회

고도화 요구 사항
1. 문자 연락 뿐 아니라 이메일, 외부메신저 앱을 이용할 수 있게 고도화
2. 여러 연락 수단에 대한 데이터를 저장하고 보여줄 수 있어야 함
3. 연락처별 대화 목록 조회 페이지 / 연락 수단 별 대화 목록 조회 페이지
기존 구조에서 변경하려다가 하지 않은 구조(변경하려다가 안 한 구조)
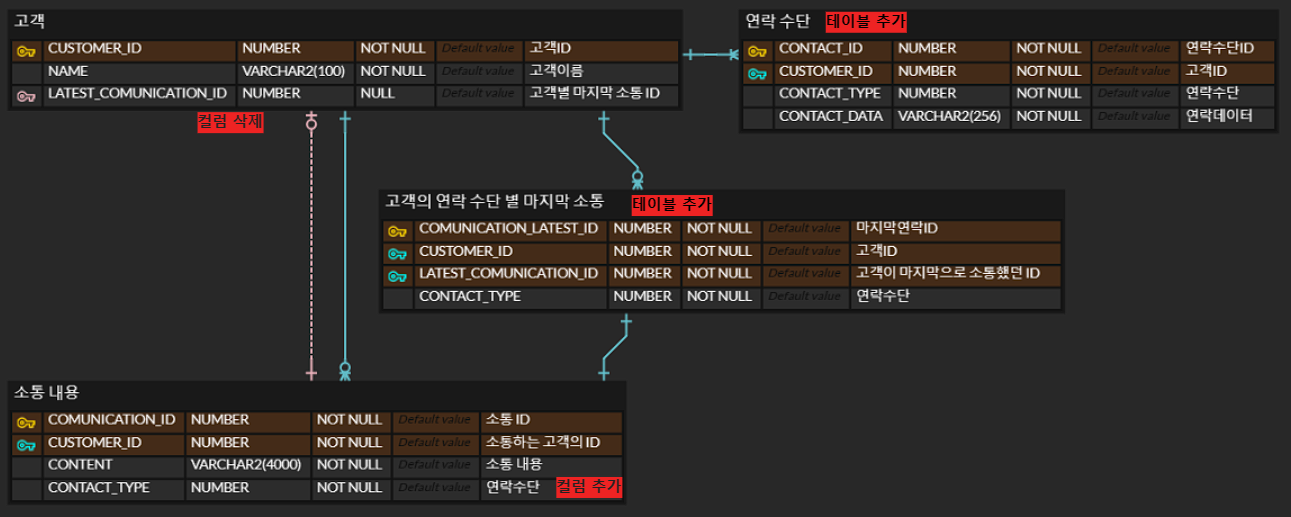
[변경 내용 요약]
-> PHONE_NUMBER 컬럼 삭제, '연락 수단' 테이블 추가
-> 소통 내용 테이블에 컬럼 추가
- CONTACT_TYPE (연락 수단)
- COMMUNICATION_LATEST_FLAG (연락 수단 별 마지막 연락인지 FLAG)
[설명]
요구사항인 연락 수단 별 대화 목록은 COMMUNICATION_LATEST_FLAG 을 이용해서 조회할 수 있다.
조회 성능을 높이려면 소통 내용 테이블에에 데이터가 6천만건 이상 있어서 INDEX가 필수이다.
그런데, COMMUNICATION_LATEST_FLAG 에 대해서 index를 추가해도 0 또는 1에 대한 데이터만 가지고 있는 컬럼이여서 index 효율이 안 나온다. 더군다나 COMMUNICATION_LATEST_FLAG 는 update 되는 컬럼이여서 index로 설정 시 update 성능을 안 좋게 한다.
===> 결론적으로 index를 추가해도 효율이 안 나오는 테이블 구조여서 다른 구조를 생각하기로 했다.

최종적으로 기존 구조에서 변경한 테이블 구조
[변경 내용 요약]
-> PHONE_NUMBER 컬럼 삭제, '연락 수단' 테이블 추가
-> 소통 내용 테이블에 컬럼 추가
- CONTACT_TYPE (연락 수단)
-> 고객의 연락 수단 별 마지막 소통 테이블 추가
연락 정보마다 타입 별로 마지막 메세지를 저장할 수 있게 모델링
위 실패한 구조에서 설명 한 대로 대화 정보 테이블은 데이터 양이 많아서 select 성능을 위해 index가 필요한데 타입별 마지막 데이터인지를 구분하기 위해 메세지 데이터 테이블에LATEST_FLAG 컬럼을 추가하여 index에 포함시키는 걸 생각해봤을 때 LATEST_FLAG는 UPDATE 되는 컬럼이고 0,1 데이터이므로 index에 적합하지 않다. 따라서 타입별 마지막인지는 새 테이블을 만들어서 저장하기로 한다.
새 테이블은 고객 별 메세지 타입 개수 만큼만 row가 생기기 때문에 데이터 양이 적어서 select 성능에 큰 문제가 없다.
CUSTOMER_ID와 CONTACT_TYPE으로 조회해서 나온 LATEST_COMUNICATION_ID을 사용해서 '소통 내용' 테이블의 PK인 CUMUNICATION_ID를 찾기 때문에 SELECT 성능이 좋다.
결론적으로 위 실패한 구조보다 SELECT 성능이 잘 나오는 구조이다.
※ 테이블 모델링 시 참고하기 위해 index에 대해 정리하였습니다.
index란
index란 데이터베이스의 읽기 작업을 향상시키기 위한 자료구조이다.
index를 사용하면 좋은 경우
- select 연산이 많고 insert,update,delete 연산이 적은 테이블
- 테이블 행의 갯수가 많은 경우 (=데이터가 많은 경우)
: 데이터가 충분히 많지 않으면 인덱싱을 활용하는게 오히려 성능이 안 좋아서 옵티마이저가 자체적으로 인덱스를 활용하지 않기도 한다.
- 인덱스를 적용한 컬럼이 where 절에서 많이 사용되는 경우
- JOIN 할 때 사용하는 컬럼 (on 부모테이블.PK = 자식테이블.FK)
- 검색 결과가 원본 테이블 데이터 2-4%에 해당하는 경우
- 해당 컬럼이 null을 포함하는 경우 (색인에 null이 제외)
- 데이터의 중복도가 낮은 컬럼 ( 카디널리티가 높은 컬럼 )
: ex) 아이디, 주소, 주민번호
검색할 대상이 줄어듬
index를 사용하면 안 좋은 경우
- 테이블의 행의 갯수가 적은 경우
- 검색 결과가 원본 테이블의 많은 비중을 차지하는 경우
- 원본 테이블의 삽입, 수정, 삭제가 빈번한 경우
- 데이터의 중복도가 높은 컬럼 ( 카디널리티가 낮은 컬럼 )
ex) 성별 컬럼: 남/여, flag 컬럼 : 0 / 1
남자로 검색해봤자 검색할 대상이 크게 줄어들지 않아서 index로 적합하지 않음
index가 DML에 미치는 영향
- index에 해당하는 컬럼으로 where, join을 하면 SELECT 성능이 좋아진다.
- INSERT/ UPDATE / DELETE는 index 데이터에 대한 추가 작업이 필요하여 성능이 떨어질 수 있다.
DML(Data Manipulation Language)이 일어났을 때의 상황
- INSERT
□기존 블록에 여유가 없을 때 새로운 데이터가 입력되면 새로운 블록을 할당 받은 후 Key를 옮기는 작업을 수
□ Index Split 작업 동안 해당 블록의 Key 값에 대해서 DML이 블로킹
□ 대기 이벤트 발생 - DELETE
□ 테이블에서 데이터가 삭제 되는 경우
- 데이터가 지워지고 다른 데이터가 그 공간 사용 가능
□ 인덱스에서 데이터가 삭제 되는 경우
- 데이터가 지워지지 않고 '사용 하지 않음' 표시만 해둠
- 테이블의 데이터 수와 인덱스의 데이터 수가 다를 수 있음 - UPDATE
□ 테이블에서 업데이트가 발생하면 인덱스는 업데이트 할 수 없음
□ 인덱스에서는 삭제가 발생한 후 생성하는 작업 과정을 거침
- 2배의 작업이 소요됨
참고
인덱스의 구조와 효율적인 사용 방법 (velog.io) : 인덱스의 구조와 효율적인 사용 방법 (velog.io)
[Database] 인덱스(Index) (velog.io)
'programming study > D-모델링,튜닝,인덱스' 카테고리의 다른 글
| [스크랩]NULLABLE-컬럼에-대한-인덱스-사용-Oracle-vs-MySQL (0) | 2024.07.02 |
|---|---|
| 통계 (0) | 2023.10.13 |